什么是分布一致性
这是一个相当灵魂拷问的问题了,在我们应对千万级甚至亿级的资源访问时,一定会用到的一个词,就是分布式
因为一台服务器的承载力是有限的,而数据库更是有限的,数据表是更更更有限的,我们只能通过横向扩容的方式来进行数据存储量和查询速度的优化
可这样会造成一个问题,分库分表后,分布式系统中,唯一主键ID的生成问题,当我们使用mysql自增长主键时,他只在本表中是唯一的, 在分布式系统中,两张表都有一张ID为1的数据,那么显然就无法使用这个自增长了
如果我们说使用uuid,也可以凑活用,但是,第一他是无序的,第二,他占用空间巨大,耗费空间。
uuid只能适用于类似生成token令牌的场景
SnowFlake
SnowFlake(雪花算法),是Twitter提出来的一个算法,其目的是生成一个64bit的整数
1位标识符,始终是0
41位的时间戳
10位的机器标识码
- 前5位代表数据中心,后面5位是某个数据中心的机器ID
12位的递增序列
- 用来对同一个毫秒之内产生不同的ID,12位可以最多记录4095个,也就是在同一个机器同一毫秒最多记录4095个,多余的需要进行等待下毫秒。
python实操
首先安装
pip install pysnowflake
然后终端启动snowflake服务
snowflake_start_server --worker=1这里的worker就是当前节点的标识
上代码:
import snowflake.client
print(snowflake.client.get_guid())
# 多次输出一下,就会发现,有递增的连续性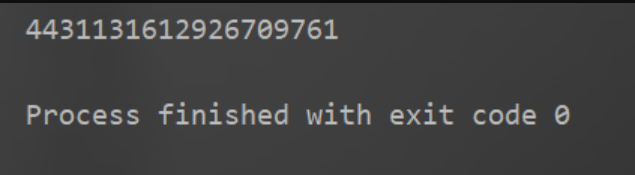
将其转换成二进制码
print(bin(4431128039883018241))
然后我们通过二进制码反推
- 第一位是标识符
- 往后41位是时间戳
从右方数,12位的递增序列,再数5位就是机器标识,这个机器标识就是某个节点的存储标识00001
但是啊,目前他是二进制,我们再将其转换为10进制
print(int('00001',2))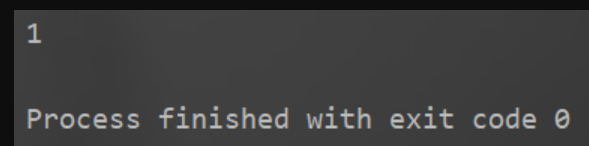
- Post link: https://www.godhearing.cn/fen-bu-yi-zhi-xing-suan-fa-xue-hua-suan-fa/
- Copyright Notice: All articles in this blog are licensed under unless otherwise stated.