前言
什么是搜索,这是一个相当简单的问题了,就是根据一个搜索词来检索出所有包含该词的数据。我们一般使用
mysql数据搜索都是通过模糊搜索来查询,但是这样就会面临一个性能问题,假如数据量超多,这样的搜索无异于自杀。基于文档式的全文检索引擎相信大家都不陌生,
Elasticsearch诞生的本意是为了解决文本搜索太慢的问题,ES会默认将所有的输入内容当作字符串来理解,对于字段类型是keyword或者text的数据比较友好。
我们已经提到,Elasticsearch专为字符串搜索而生,在建立索引的时候针对字符串进行了非常多的优化,在对字符串进行准确匹配或者前缀匹配等匹配的时候效率是很高的。
谈论到搜索引擎,就一定会涉及到两个概念,正向索引和反向索引。听上去这是两个完全不同的数据结构。但是实际上,正向索引就好比我们的书籍,每本书都有目录,这就是一种正向索引,能够通过文档去查找关键词。
而反向索引,和正向索引是完全相反的,它将关键词作为索引, 去查找哪个文档包含了这个关键词,就拿上边的例子,正向索引是通过楼层去找店铺,而反向索引,就是你知道店铺的某一个字,商场导航给你提供了包含这个字的所有店铺,这样就极大的缩小了查找范围。
Docker配置
拉取镜像
docker pull elasticsearch:7.2.0运行镜像
docker run --name es -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" -d elasticsearch:7.2.0容器别名我们就用缩写es来替代,通过 9200 端口并使用
Elasticsearch的原生传输协议和集群交互。集群中的节点通过端口 9300 彼此通信。如果这个端口没有打开,节点将无法形成一个集群,运行模式先走单节点模式。
此时,我们如果要加一些功能,就得改一些配置,就好像django的Settings配置一样。
Docker提供了cp命令来拷贝容器内部的文件
我们只要拷贝elasticsearch.yml
docker cp 容器id:/usr/share/elasticsearch/config/elasticsearch.yml ./elasticsearch.yml也可以将文件拷贝路径指定为绝对路径
打开文件,可以加一些自己的配置
cluster.name: "docker-cluster"
network.host: 0.0.0.0
http.cors.enabled: true
http.cors.allow-origin: "*"然后停止正在运行的容器,并且删除它
docker stop 容器id
docker rm $(docker ps -a -q)再次启动,只不过不同的是,这次我们需要通过-v命令把我们刚刚修改的文件配置挂载到容器内部去。
docker run --name es -v E:\elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" -d elasticsearch:7.2.0这里需要注意一点,就是在Win10宿主机里需要单独设置一下共享文件夹,这里我设置的共享文件夹叫做es,如果是Centos或者Mac os就直接写真实物理路径即可。
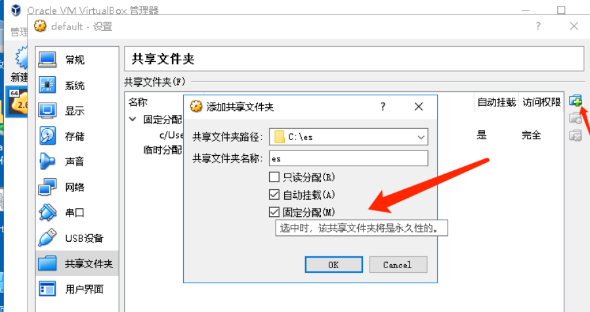
随后,重启Docker,输入命令进入默认容器:docker-machine ssh default
在容器根目录能够看到刚刚设置的共享文件夹,就说明设置成功了。
另外还有一个需要注意的点,就是Elasticsearch存储数据也可以通过-v命令挂载出来,如果不对数据进行挂载,当容器被停止或者删除,数据也会不复存在,所以挂载后存储在宿主机会比较好一点,命令是:
docker run --name es -v /es/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml -v /es/data:/usr/share/elasticsearch/data -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" -d elasticsearch:7.2.0python配置
首先安装pip3 install elasticsearch
建立检索实例
from elasticsearch import Elasticsearch
es = Elasticsearch(hosts=[{"host":'Docker容器所在的ip', "port": 9200}])建立索引
# 建立索引
result = es.indices.create(index='godhearing', ignore=400)
print(result)删除索引
result = es.indices.delete(index='godhearing', ignore=[400, 404])
print(result)插入数据
data = {'title': '天听', 'url': 'http://123.com','content':"好耶耶耶"}
result = es.index(index='godhearing',body=data)
print(result)index()方法会自动生成一个唯一id
也可以使用create()方法创建数据
不同的是create()需要手动指定一个id
修改数据
data = {'content':"啊哈哈哈哈哈哈哈嗝!"}
result = es.index(index='godhearing',body=data, id='插入数据时返回的id')
print(result)修改之后,仅剩余此字段
删除数据
result = es.delete(index='godhearing',id='插入数据时的ID')
print(result)查询数据
result = es.search(index='godhearing')
print(result)全文检索
mapping = {
'query': {
'match': {
'content': '嗝'
}
}
}
result = es.search(index='godhearing',body=mapping)
print(result)- Post link: https://www.godhearing.cn/ji-yu-docker-pei-zhi-elasticsearch-quan-wen-jian-suo/
- Copyright Notice: All articles in this blog are licensed under unless otherwise stated.