前言
自从mysql被oracle收购以后,PostgrelSQL逐渐成为开源关系型数据库的首选。并且就算mysql没有被收购,它所暴露出的问题也很难让人不追求新的数据库
比如,Emoji表情坑随后推出这个utfmb4
与时俱进之下,我们不采用普通的安装方式,而使用Docker来进行安装使用
Docker安装PostgrelSQL
第一步,拉取镜像
docker pull postgres:11.1然后,启动
docker run -d --name dev-postgres -e POSTGRES_PASSWORD=root -p 6432:5432 postgres:11.1这里的
POSTGRES_PASSWORD是PostgrelSQL的用户密码,自己制定一个就可以了。
进入命令行操作一下
docker exec -it dev-postgres bash
psql -h localhost -U postgres这样就进入了容器内部的命令行
下面来介绍一下PostgrelSQL的一些命令
PostgrelSQL命令
数据库操作
建立数据库
create database 库名使用数据库
\c 库名查看所有数据库
\l查看所有数据库,并且展示详细信息
\l+删除数据库
drop database 库名表操作
创建表
create table 表名(字段 类型 属性)
例子:
create table empsal(
id int4 not null,
name varchar(20) not null,
primary key(id)
)with(oids=FALSE);
primary key代表的是主键,和其他的关系型数据库一致,不过,他可以建立一个或者多个主键,
查看所有表
\d删除表
drop table 表名更新表结构
alter table 表名 add 字段名 类型 属性;
例子:
alter table article add email varchar(40);查看表结构
\d 表名PostgreSQL 模式(schema)
PostgreSQL 模式(SCHEMA)可以看着是一个表的集合。一个模式可以包含视图、索引、数据类型、函数和操作符等。相同的对象名称可以被用于不同的模式中而不会出现冲突,例如 schema1 和 myschema 都可以包含名为 mytable 的表。
使用模式的优势:
- 允许多个用户使用一个数据库并且不会互相干扰。
- 将数据库对象组织成逻辑组以便更容易管理。
- 第三方应用的对象可以放在独立的模式中,这样它们就不会与其他对象的名称发生冲突。
模式类似于操作系统层的目录,但是模式不能嵌套。
创建模式
create schema myschema;在指定模式里创建表,如:
CREATE TABLE myschema.user (
...
);删除一个空的schema,如:
drop schema myschema;删除一个模式以及模式里面所有的对象,如:
drop schema myschema CASCADE;在创建表时,如果没有指定schema,则会自动被归属到一个叫做public的模式中,也就是公共的。
所以,我们创建表时,这两种创建方式是一样的效果。
create table tablename();
create table public.tablename();模式权限的更改
缺省时,用户看不到模式中不属于他们所有的对象。为了让他们看得见,模式的所有者需要在模式上赋予 USAGE 权限。为了让用户使用模式中的对象,我们可能需要赋予额外的权限, 只要是适合该对象的。
用户也可以允许在别人的模式里创建对象。要允许这么做, 我们需要赋予在该模式上的 CREATE 权限。 请注意,缺省时,每个人都在 public 模式上 有 CREATE 权限。这样就允许所有可以连接到 指定数据库上的用户在这里创建对象。如果你不允许这么做, 你可以撤销这个权限:
REVOKE create on schema public from PUBLIC;我们可以通过GRANT和REVOKE命令来分别的添加或撤销模式中的相应权限。这条命令中,我们移除了public模式中的CREATE权限。注意,我们使用了两个public,分别为一个大写和一个小写。小写的public指的是模式,实际使用中可以被替换为数据库中其他任意有效的模式名。
而大写的PUBLIC是一个特殊的关键字,代表了all users。实际使用中可以被替换为一个特定的角色名或者以逗号分隔的角色名列表。
使用\dn+命令查询修改后的权限,发现权限信息中第二行里的C权限已经被移除,证明之前的REVOKE命令是有效的。现在,除了postgres用户以外的用户将不再能在public模式中创建表、视图或其他对象。
数据操作
插入数据
insert into 表名 values(对应数据)
也可以根据字段来进行添加
insert into 表名(字段名) values(对应数据)这里要提一点,如果想使用可视化工具来操作PostgrelSQL的话,(例如navicat),无法像mysql一样手动设置属性自增长,而是使用序列的形式来实现自增长
创建序列
create sequence serial start 1
这句话的意思是,创建一个名为serial的序列,从1开始计数查看结构

随后,将需要设置的字段的默认值设为序列增长即可
alter table 表名 alter column 要自增长的字段 set default nextval(序列名)
例子:
ALTER TABLE "public"."article" ALTER COLUMN "id" SET DEFAULT nextval('serial');
删除数据
delete from 表名 where 条件
例子:
delete from user where name='李四'更新数据
update 表名 set 修改后的字段对应的数据 where 条件
例子:
update user set name='张三' where name='李四'窗口函数
聚合函数相信大家都用过,像sum、min、avg等,一般是和group by搭配使用,窗口函数和聚合函数类似,也是计算一些行集合的数据,和常规的聚合函数不同的是,窗口函数不会将参与计算的行合并成一行输出,而是将计算出来的结果带回到了计算行上。
注意,窗口函数必须和over字句搭配使用,over字句包含partition by和order by两部分,分别用来分组和确定组内输出顺序,他们都是可选的
如果两个都省略,整个表会被作为一个分组
我们来举个例子吧,假设我们有一张表,分别有部门,员工,工资三个字段
假设我们要查询每个部门的平均工资以及所有员工的对比,在传统做法下,我们需要先通过group by分组,再用表连接统计一下上面的结果
而使用窗口函数,可以简化很多
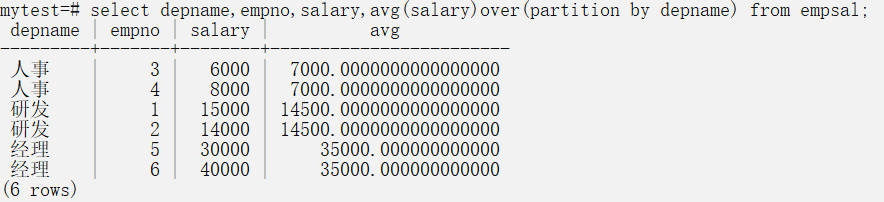
而使用order by的话,会造成怎样的结果呢
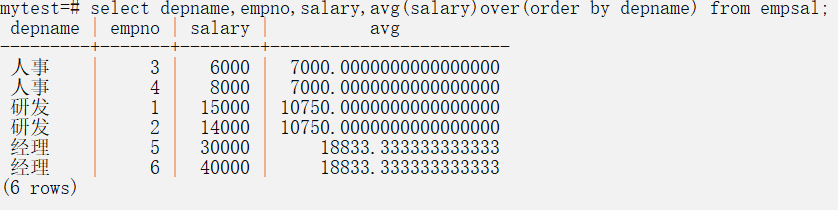
可以看到,第一个是人事部门的平均工资,第二个,是研发和人事的平均工资,第三个,就是所有部门的平均工资。使用的时候要特别注意。
python使用PostgrelSQL
和使用mysql一样,先装三方库
pip3 isntall psycopg2然后和mysql一样使用
import psycopg2.extras
conn = psycopg2.connect(host='localhost', port=6432, user='postgres', password='root', database='mytest')
cursor = conn.cursor(cursor_factory=psycopg2.extras.DictCursor)
cursor.execute('SELECT * FROM empsal;')
result = cursor.fetchone()
print(result)ok,完成
- Post link: https://www.godhearing.cn/postgrelsql/
- Copyright Notice: All articles in this blog are licensed under unless otherwise stated.