前言
Saeweedfs是一个由golang语言开发的分布式对象存储系统,很适合做图片服务器,性能很好,并且可兼容挂载提供路径访问的方式,使得文件储存在云端变得非常方便。
seaweedfs的特点:
- 可以成存储上亿的文件(根据你硬盘大小变化)
- 速度刚刚的
安装
安装呢,需要从官网上下载对应系统的版本,地址,我以windows为例,可以看到,下载下来的是个压缩包,解压后就是一个exe安装包,但是我们直接点是没有用的,所以,我们通过命令来进行
首先呢,我们查看一下所有的命令,得知,可以使用master命令来进行启动
weed master -ip=127.0.0.1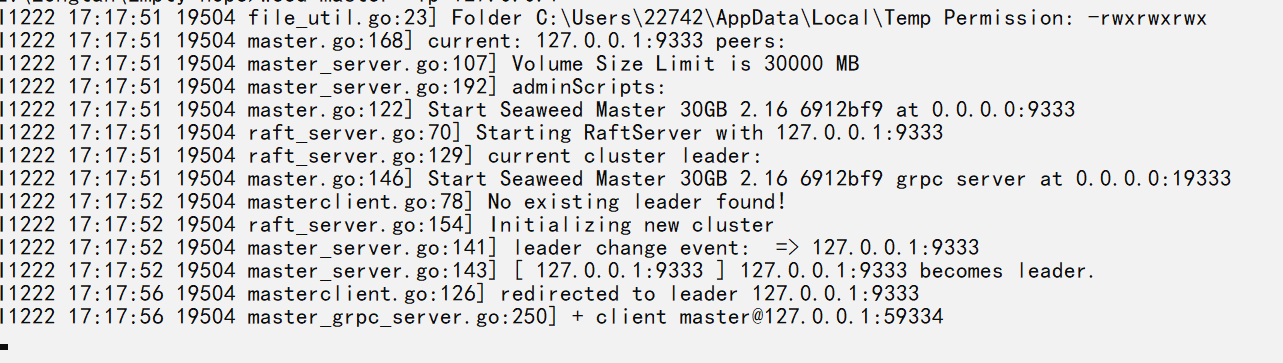
master节点设置好了之后,继续看文档,来设置volume节点
如果没有data这个文件夹,就自己创建一个
mserver是master节点地址
weed volume -dir="./data" -max=10 -mserver="127.0.0.1:9333" -port=9000 -index=leveldb
然后访问一下http://localhost:9333/即可,好,一切ok,再查看一下状态
"http://127.0.0.1:9333/cluster/status?pretty=y"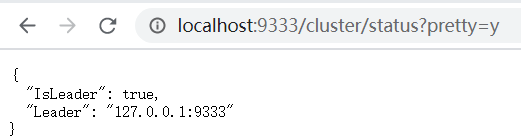
使用
继续看文档,如果要写入文件,则需要发送请求到/dir/assign来获取fid和volume服务器url

然后将fid拼接,发送文件,这里用postman测试一下
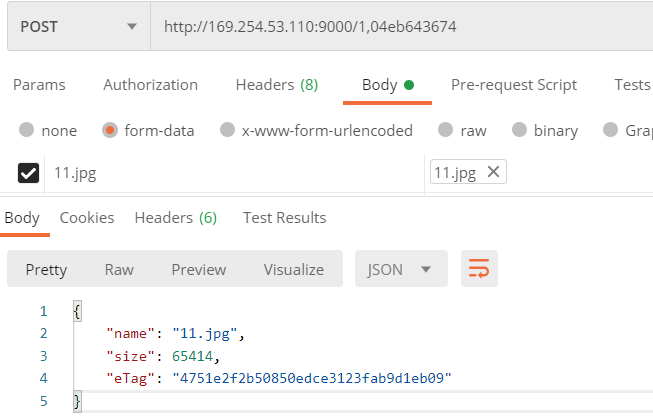
发送成功,这时候你可以将fid存下
fid:开头的数字3表示卷ID。逗号后是一个文件密钥01和一个文件
cookie 637037d6。卷ID是32位无符号整数。文件密钥是一个无符号的64位整数。文件cookie是32位无符号整数,用于防止URL猜测。
文件密钥和文件cookie均以十六进制编码。可以使用自己的格式存储<卷ID,文件密钥,文件cookie>元组,也可以将
fid存储。
然后,怎么访问呢,当然是通过刚刚保存的fid啦,不过要注意,一定要先查找卷服务器的url,http://localhost:9333/dir/lookup?volumeId=卷ID,然后通过返回的publicUrl这个域名来进行查找
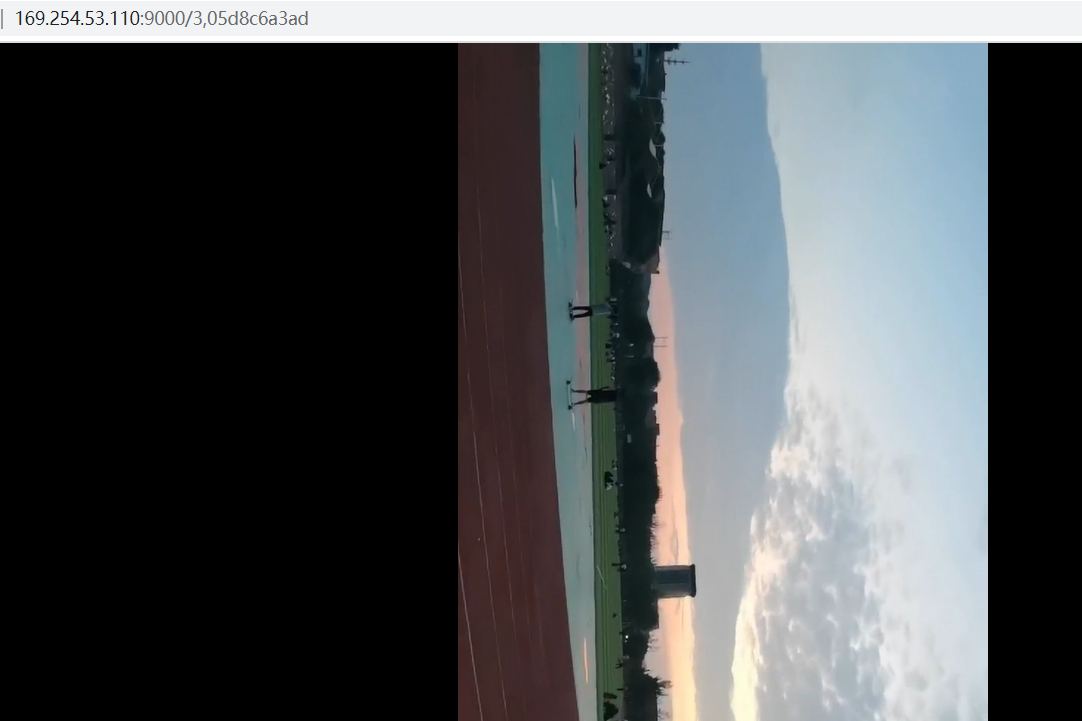
要注意,这时,不只是可以用这个方式来访问,还可以使用
# 卷id/密钥+文件cookie/文件名
http://localhost:8080/3/01637037d6/my_preferred_name.jpg
# 卷id/密钥+文件你cookie.后缀名
http://localhost:8080/3/01637037d6.jpg
还有其他方法,不一一列举啦
http://localhost:8080/3,01637037d6.jpg
http://localhost:8080/3/01637037d6
http://localhost:8080/3,01637037d6如果要获取图像的缩放版本,则可以添加一些参数:
http://localhost:8080/3/01637037d6.jpg?height=200&width=200
http://localhost:8080/3/01637037d6.jpg?height=200&width=200&mode=fit
http://localhost:8080/3/01637037d6.jpg?height=200&width=200&mode=fill要更新,请发送另一个具有更新文件内容的POST请求,就是fid不变的情况下,再发一个新的文件,它就会自动给覆盖掉
删除的话,直接发送delete请求到相同的地址,删除成功会给你返回一个size,文件不存在的话这个size的值为0
何谓分布式,当然是可以分布啦,它本身提供了机架感知和数据中心感知复制,SeaweedFS在卷级别应用复制策略。因此,在获取文件ID时,可以指定复制策略。例如:
curl http://localhost:9333/dir/assign?replication=001复制参数选项包括:
000:无复制
001:在同一机架上复制一次
010:在不同机架上复制一次,但数据中心相同
100:在不同的数据中心复制一次
200:在两个不同的数据中心复制两次
110:在不同的机架上复制一次,在不同的数据中心复制一次还可以在启动主服务器时设置默认复制策略。额..暂时没有搞,稍后补
python中使用seaweedfs
我们如果要在python中使用这个seaweedfs,则需要先安装一个包
pip install pyseaweed
使用的方法,非常的简单,在GitHub上,作者也给写的相当明白了
from pyseaweed import WeedFS
# File upload
w = WeedFS("localhost", 9333) # weed-fs master address and port
fid = w.upload_file("n.txt") # path to file
# Get file url
file_url = w.get_file_url(fid)
# Delete file
res = w.delete_file(fid)
# res is boolean (True if file was deleted)我们简单的封装一下
from pyseaweed import WeedFS
# 上传文件
def upload_file(seaweed_address,file,name):
w = WeedFS(*seaweed_address)
fid = w.upload_file(stream=file,name=name)
if fid:
return fid
else:
return False
#
# 查看文件的域名
def get_file_url(seaweed_address, fid):
w = WeedFS(*seaweed_address)
file_url = w.get_file_url(fid)
if file_url:
return file_url
else:
return '该资源不存在'
def del_file(seaweed_address,fid):
w = WeedFS(*seaweed_address)
res = w.delete_file(fid)
return res # True or False这里为什么要指定stream和name呢,这是因为如果传一个参数,就必须是文件的路径,如果不传文件路径,就只能将他的数据流和名字传进来。
我们使用视图来测试一下吧,seaweed_address是我自己配置的一个地址,这个可以写死,也可以写成元组,然后像我这样使用
class avatar_upload(APIView):
def post(self,request):
avatar = request.FILES.get('avatar')
# 调用文件存储系统,将返回的fid存下
for chunk in avatar.chunks():
fid = upload.upload_file(USER_AVATAR,chunk,avatar.name)
print(fid)
return Response({})ok,完美,不过需要注意的是,在本地是没法测的,我也在找这个问题,服务器上是没有问题
- Post link: https://www.godhearing.cn/seaweedfs/
- Copyright Notice: All articles in this blog are licensed under unless otherwise stated.