前言
sqlalchemy在1.4版本也终于是支持了异步,同时他也是更新了很多2.0操作,本文就以异步orm的方式来操作mysql,感受一下异步的魅力。
安装
首先就是要保证你的sqlalchemy是1.4以上的,同时,pymysql等驱动也不支持异步,所以要改用新的驱动。
pip install sqlalchemy==1.4.1
pip install aiomysql连接方式与之前略有不同,主要是驱动的转换,不过有关异步的东西都在sqlalchemy.ext.asyncio里面,感兴趣的可以去看一下源码。反正我是没兴趣了。
创建会话的引擎,从create_engine改成了create_async_engine,配置上自己的参数即可。驱动我们用aiomysql代替pymysql
engine = create_async_engine(f"mysql+aiomysql://{MYSQL_USERNAME}:{MYSQL_PASSWORD}@{MYSQL_HOST}/{MYSQL_DATABASE}?charset=utf8mb4", pool_pre_ping=True)创建会话
SessionLocal = sessionmaker(class_=AsyncSession, autocommit=False, autoflush=False, bind=engine)简单封装一下使用,毕竟面向对象语言。
async def get_db() -> Generator:
"""
获取sqlalchemy
"""
async with SessionLocal() as db:
yield db好了,那就简单查询一下。
async def get_series(db: AsyncSession):
res = await db.execute(select(User))
user = res.scalars().all()scalars主要作用是把数据映射到orm类上去,不然得到的就是一行一行的查询结果
可以分页,也可以获取单个结果,这都是基本操作了,有一些小变化,问题不大。
async def get_series(db: AsyncSession, size: int, page: int):
res = await db.execute(select(User).limit(size).offset((page - 1) * size))
user = res.scalars().all()
'''
series = res.scalars().first()
'''预加载字表
预加载主要有
lazyload()
延迟加载 -可通过 lazy=‘select’ 或 lazyload() 选项实现。
这是默认的加载方式,当需要加载字表的时候再进行数据库访问,所以一对多的时候可能会出现多次访问数据库的问题。
joinedload()
用于查询一对多,采用左加载left join。(如果要改为inner join ,则加参数**joinedload(User.addresses,innerjoin=True)**)
联合加载 -可通过 lazy=‘joined’ 或 joinedload() 选项,此加载形式将联接应用于给定的select语句,以便在同一结果集中加载相关行。联合预加载在 加入的热切装载 .
注意:只能加载一个数据
subqueryload()
子查询加载 -可通过 lazy=‘subquery’ 或 subqueryload() 选项,此加载形式发出第二个select语句,该语句重新声明嵌入在子查询中的原始查询,然后将该子查询联接到要加载的相关表,以一次加载相关集合/标量引用的所有成员。子查询预加载的详细信息位于 子查询预加载 .
多方关联数据集合很大时使用subqueryload,一次查询数量不超过500条则使用selectinload()更合适。
总共2条SQL语句,第1条查询user,第2条填充user.addresses,使用INNER JOIN,不改变一方查询结果,且子查询的字段仅为一方表主键
缺点:如果查询中使用了first、limit、offset,则必须同时使用order_by,否则可能产生错误结果
selectinload()
用户查询多对一,加载时选择 -可通过 lazy=‘selectin’ 或 selectinload() 选项,此加载形式发出第二个(或更多)select语句,将父对象的主键标识符组装到in子句中,以便相关集合/标量引用的所有成员都按主键一次加载。加载中的选择详细信息位于 加载时选择 .
注意:可以加载多个数据
当要同时加载多个不同的多方关联表数据(及需要join多个表)时使用selectinload
总共1+(N / 500)条SQL语句,第1条查询user,第2条(及以后)填充user.addresses,不会产生笛卡尔积问题,不会多次join,无需order_by,性能高
缺点:一个SQL语句一次只能获取多方关联数据集合的500条数据,集合数据量超过500时,将每500个发出一个SQL
缺点:对于复合主键,selectin加载不是平台无关的,已知支持的DBAPI为PostgreSQL, MySQL, SQLite,对于不支持的DBAPI将抛异常
raiseload()
如果进行了额外的加载查询,则报错。
加荷 -可通过 lazy=‘raise’ , lazy=‘raise_on_sql’ ,或者 raiseload() 选项,此形式的加载在通常发生延迟加载的同时触发,除非它引发ORM异常以防止应用程序进行不需要的延迟加载。提升负载的介绍在 使用raiseload防止不需要的懒惰负载 .
noload()
不进行加载,值直接赋值为空。
无负载 -可通过 lazy=‘noload’ ,或者 noload() 选项;此加载样式将属性转换为永远不会加载或具有任何加载效果的空属性。”“noload”是一个非常罕见的加载程序选项。
鉴于异步方法,我建议要么使用立即加载要么就不要加载。
使用方法:
results = await db.execute(select(User).options(joinedload(Message.message_user)))
user=results.scalars().all()注意:记得配置relationship
然后,测试一下连接查询
sql = select(Series.title, Suit.title).join(Series, Suit.series == Series.id, isouter=True).where(Series.id == 9).limit(size).offset((page - 1) * size)
res = await db.execute(sql)
series = res.all()注意一点,如果是连接查询的话,就不要用scalars了,否则只会取到一个Series对象。
查询函数func
对于count等查询方式,使用func进行查询,示例
from sqlalchemy import select, func
async with db_session.begin():
total = (await db_session.execute(func.count(Message.id))).first()[0]修改
修改只需要读取到相关的model,然后修改字段,然后执行flush即可,如下:
@t_route.get("/users")
async def get_users(session: AsyncSession = Depends(get_db_session)):
async with session.begin():
result = await session.execute(
select(User)
)
f = result.scalars().first()
f.password=mininet
await session.flush()
return user_schema.from_orm(f)增加
示例代码
@t_route.post("/group")
async def create_group(name: str):
async with AsyncSession(engine) as session:
async with session.begin():
permission = Group(name=name)
session.add(permission)
await session.flush()
return True还有一种插入方式,也需要掌握(主要是orm的原生异步好像还缺了不少功能)
@t_route.post("/group")
async def create_group(name: str):
async with AsyncSession(engine) as session:
async with session.begin():
await session.execute(
Group.metadata.tables[Group.__tablename__],[{"name":name}]
)
return True测试一下性能
既然费尽心力改成了异步,那自然是要试试他的性能的。就一张单表查询,做了分页查询,数据量不是很大的情况下。
测试使用的框架是fastapi,一个简单的查询,没有任何骚操作。我们继续使用鼎鼎有名的ApacheBench进行压测。
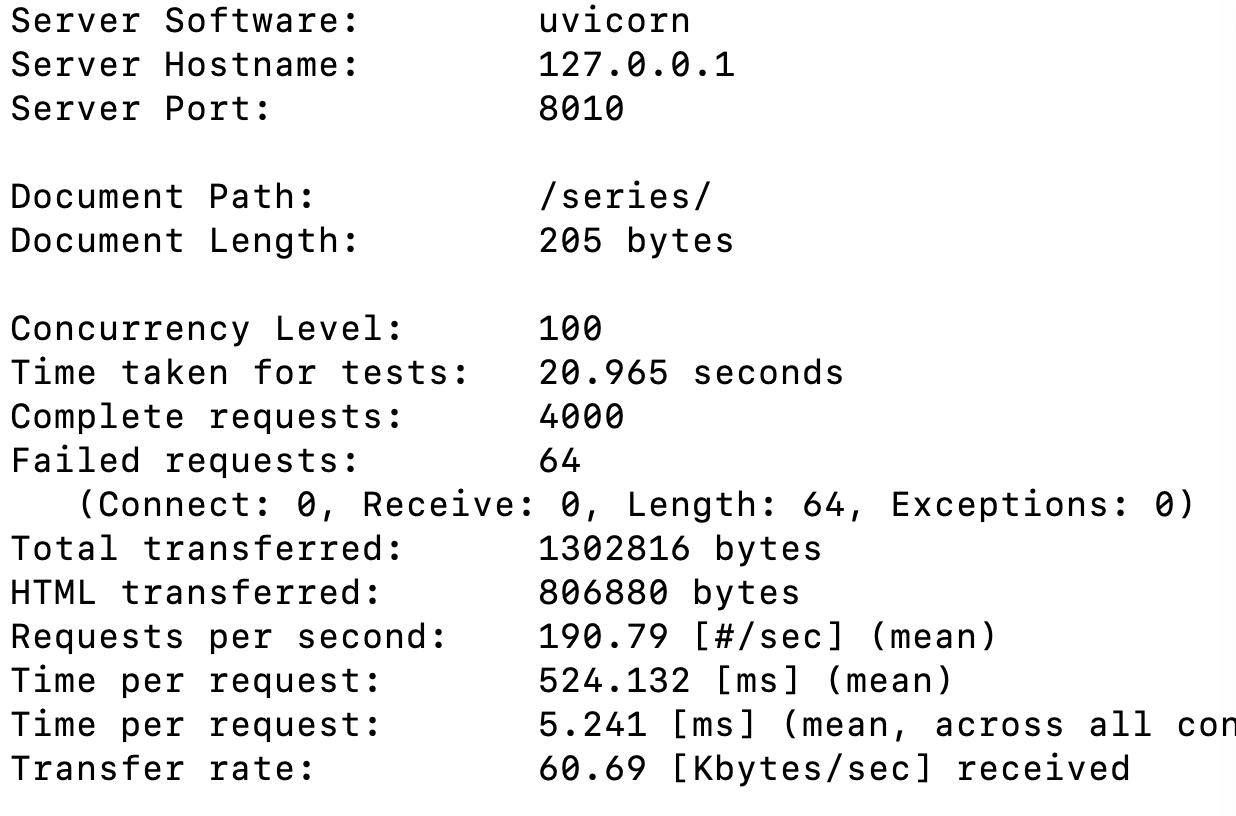
带数据库操作的情况下,qps100,消耗了二十秒,并且还有失败的。
ps:就是因为看到了这个结果我才要励志要把他搞成异步的。
好吧,虽然是单进程模式,但是这结果显然差劲。
用上了异步,我们再测一下
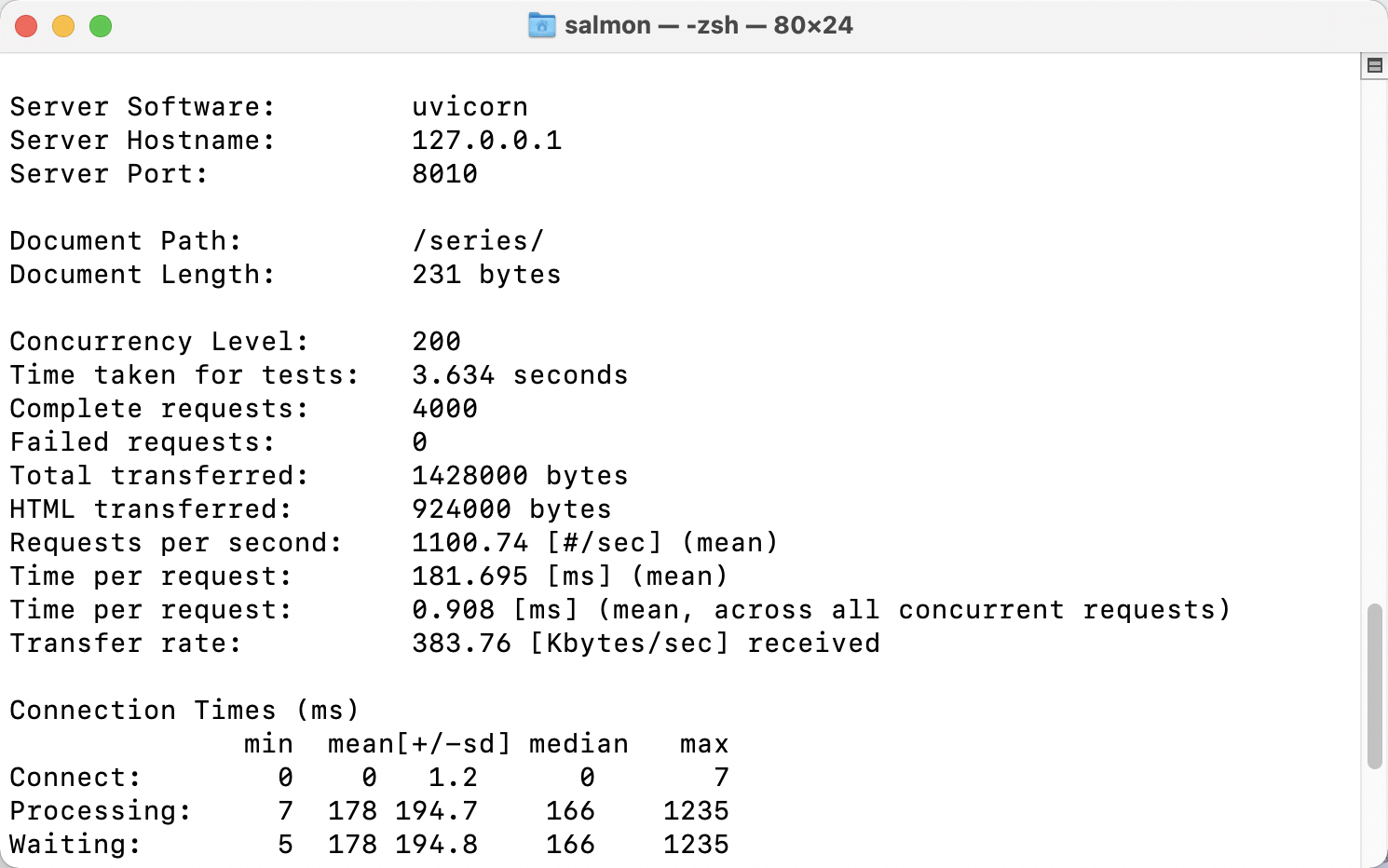
尽管不是那么的正规压测,但是显而易见,在200qps的压测下,表现几乎要追上go了。自我催眠
那,测一下go…,虽然python去找golang测速度有点找虐。
使用的gin框架,调整成生产模式单进程开始。
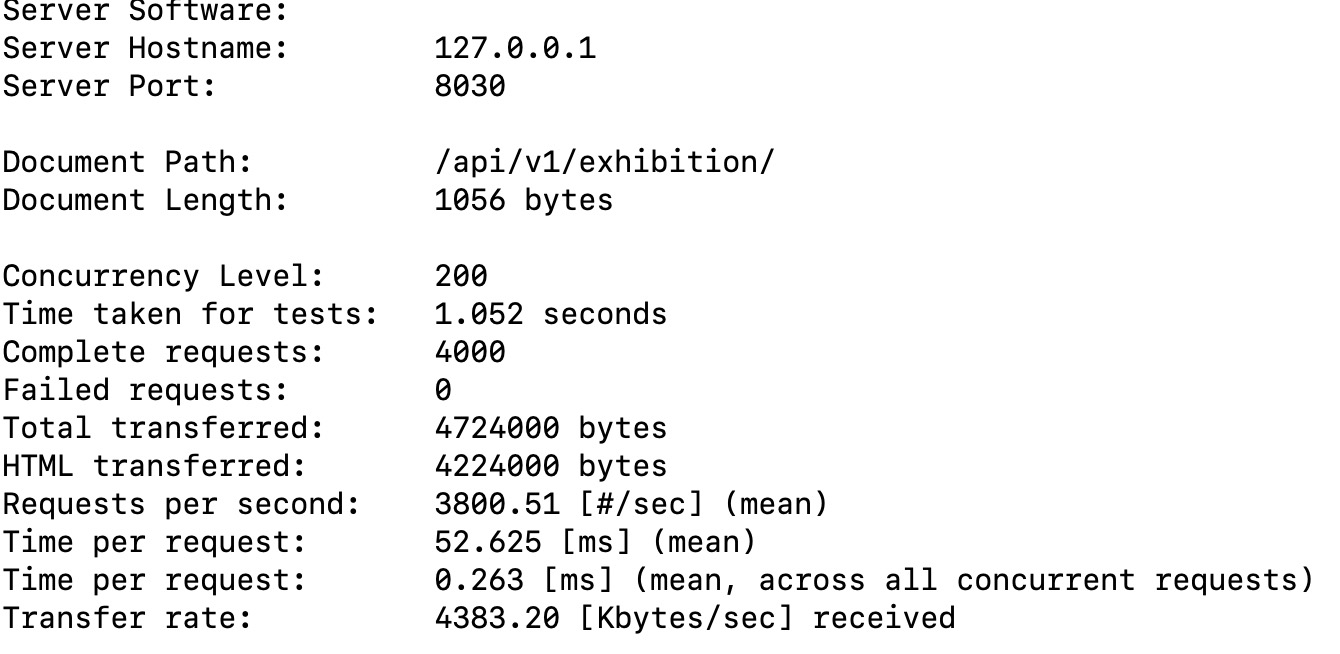
额,好吧,差距还是巨大的,不找虐了。
- Post link: https://www.godhearing.cn/sqlalchemy-yi-bu-cao-zuo/
- Copyright Notice: All articles in this blog are licensed under unless otherwise stated.