前言
这是一次全新的挑战,在我放弃摆烂之后。以下系列笔记出自于吴恩达老师的机器学习教程。
什么是机器学习
机器学习的定义,网络上关于机器学习的定义是非常多的,在吴恩达老师的课上,给总结来说就是:一门没有明确编程的情况下,让计算机学习的科学。
机器学习的类型
监督学习
监督机器学习是指学习从x到y或输入(input)到输出(output)映射的算法,监督学习的关键特征是,开发者提供i学习算法示例以供学习,这包括正确答案。并且是通过查看输入x和所需输出标签y的正确对,学习算法最终学会只接受输入而无需输出标签,并给出输出的合理准确的预测或者猜测。
举例:
| INPUT(x) | OUTPUT(y) | APPLICATION |
|---|---|---|
| 录音-> | 文本 | 语音识别 |
| 邮件-> | 垃圾邮件?(0/1) | 垃圾邮件过滤 |
| 英语-> | 汉语 | 机器翻译 |
这些例子中,通过输入,和控制想达到的输出产生了很多我们现在很常用的应用,这些都是监督学习所针对训练好的程序。在这所有这些应用程序中,将首先使用输入(input)示例x,和正确答案(output),标签y,来训练模型,在模型从这些输入、输出中学习之后,他们可以采用一个全新的输入x,这是他之前从未见过的,并尝试产生适当的相应输出y,
回归算法
假设现在有一个要预测房价走势价值的程序,这个程序要结合从房子的面积和价格可以得到这样的图:
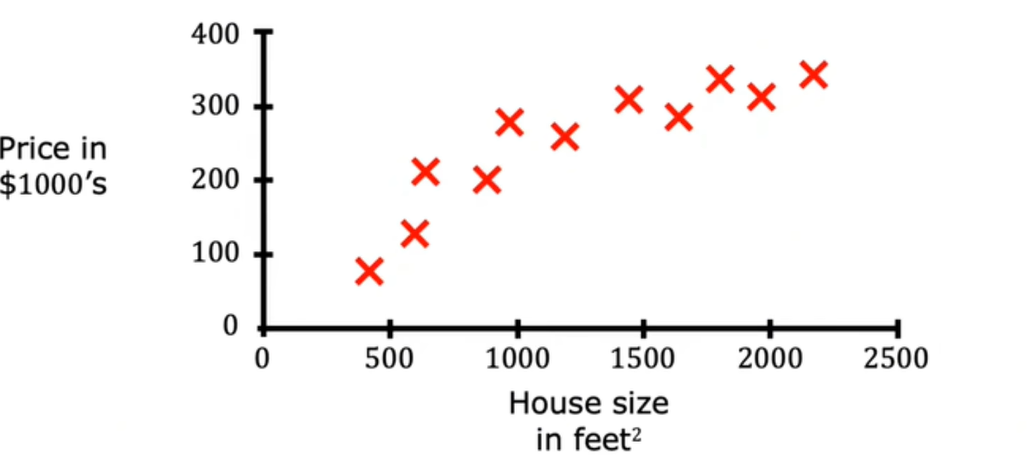
学习算法要做的可能就是绘制一个这样的数据直线,并从直线上读取:
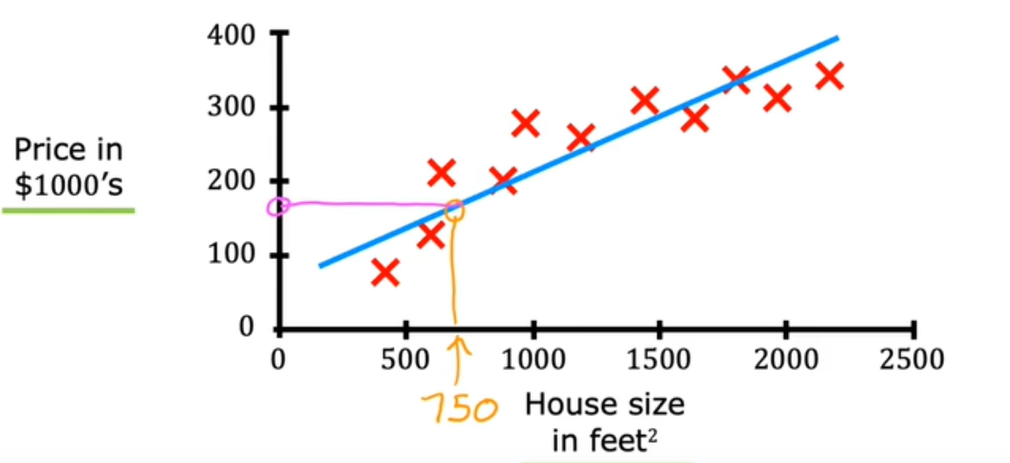
但拟合直线并不是可以使用的唯一学习算法,还有其他可以更好的用于此应用程序的方法,比如,拟合直线时,可能会觉得拟合曲线更好
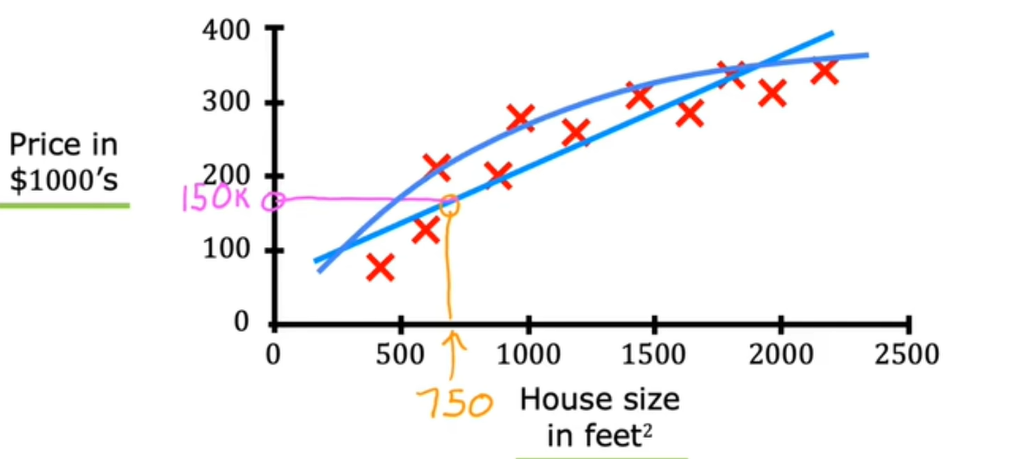
这是一个比直线稍微复杂或更复杂的函数,如果你这样做并在这里做出预测,他就是一个接近200的甚至还会更多的数字。也就是说,它可以生成一个不可预测的数字,这个数字并不存在于现有的数据集中。
分类算法
以乳腺癌检测作为一个分类问题的例子,假设你在做一个机器学习系统,让医生有一个诊断工具来检测乳腺癌,利用病人的医疗记录,试图弄清楚一个肿块的肿瘤是否是恶性的,意味着是癌症或危险的,如果中流矢良性的,意思是你只知道这只是一个肿块,不是癌症,也没有那么危险。
所以数据集里有各种大小的肿瘤,这些肿瘤是良性,标记为0,或者是恶性的,标记为1,然后你可以把你的数据绘制在这样的图表上:
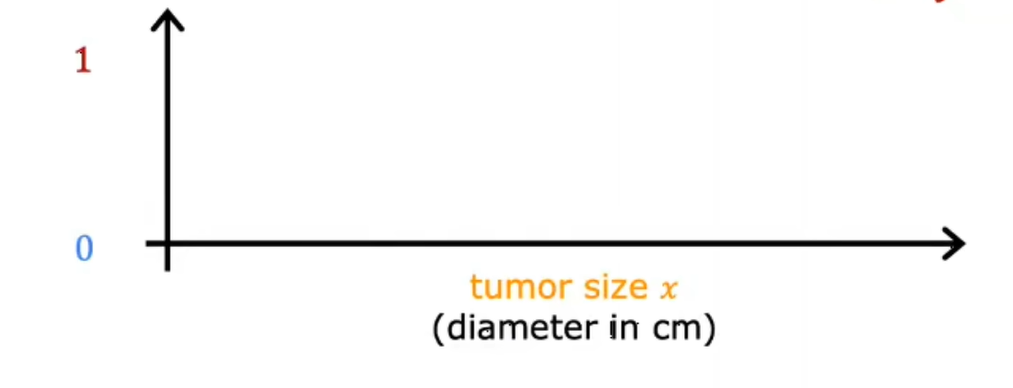
x轴代表肿瘤的大小,y轴只代表两个值,0还是1,取决于肿瘤是良性还是恶性,这与回归不同的一个原因是,我们只试图预测一小部分可能的输出或类别。
这与回归不同,回归试预测无限多个可能的数字中的任何一个,而这里只有两个可能的输出。
还可以将这个数据集绘制在像这样的一条线上:

可以用圈和叉来表示良性和恶性。如果正好处于叉和圈的中间,这时,你的系统会把这个肿瘤分为良性还是恶性?这是需要解决的问题。
在分类问题中,还可以有两个以上可能的输出类别。也许你的学习算法可以输出多种类型的癌症诊断,比如有两种类型的癌症,type1和type2:
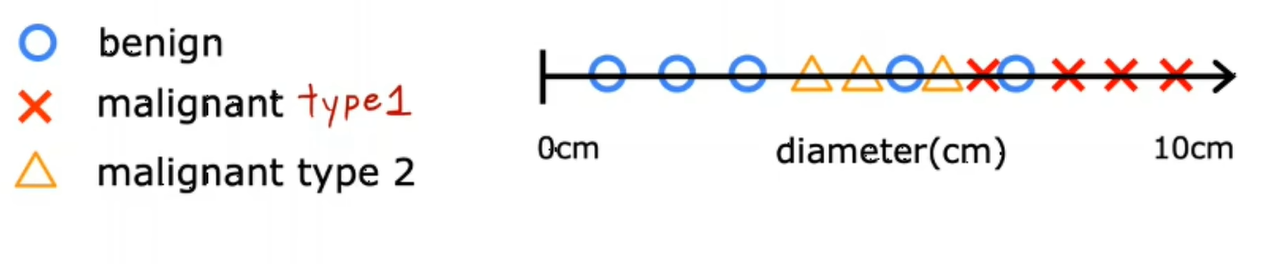
此时,该算法将有三种可能的输出类型。
在分类上,术语:输出类(classes)和输出类别(category)经常互换使用,所以当两个当引用输出时,意思是一样的。
小结:
预测类别,类别不一定是数字,它可以使非数字,例如给一张图片,它可以预测是猫还是狗,或者是上方的例子,良性还是恶性,类别也可以是数字,比如0、1、2,但当你解释这些数字时,分类与回归的不同之处在于,分类预测的是一个小的,有限的一套可能的产出类别。(事先定好的数据集,比如只有012,但是输出不可能是1.5或者0.7)。
在我们一直研究的监督学习的例子中,我们只有一个输入值,比如肿瘤的大小,但是也可以使用多个输入值来预测输出。
比如上方的例子,除了输入是肿瘤的大小,假设也有每个病人的年龄,现在新的数据集有两个输入,年龄和肿瘤大小,绘制这个新的数据集就是这样的:
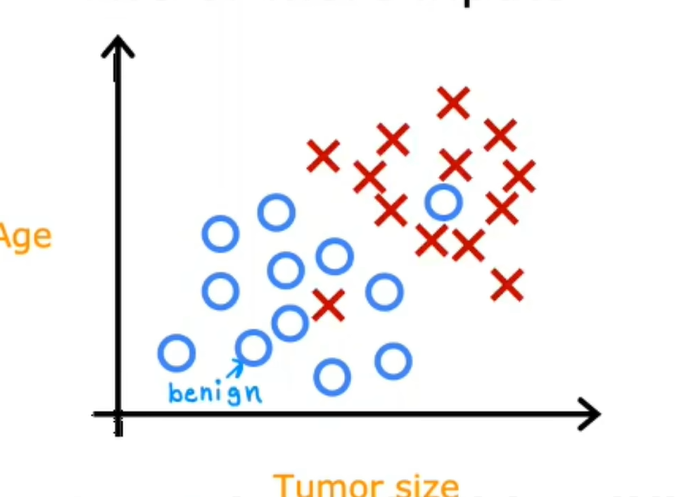
如果有一个新的病人,就会从x和y轴同时取值:
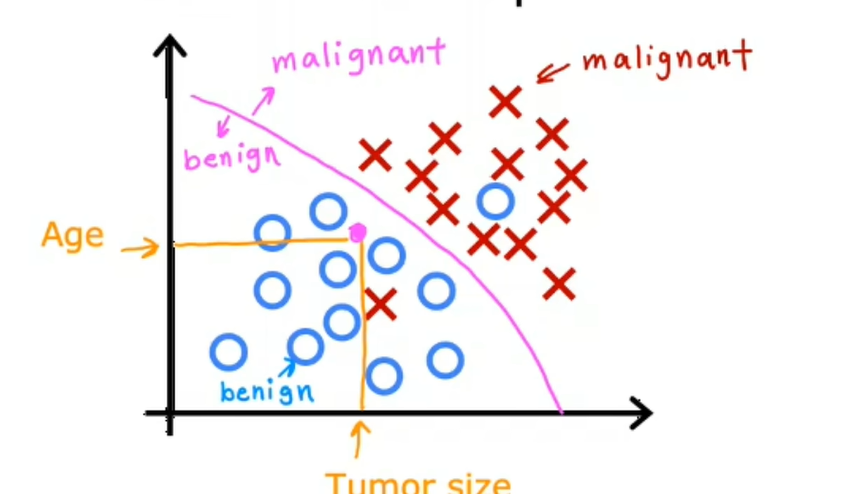
学习算法可能要做的是找到一些边界来区分恶性和良性的肿瘤(粉色的线),因此,学习算法必须决定如何将边界线拟合到这些数据上,学习算法找到的边界线将帮助医生诊断。
监督学习总结:
学习算法从正确答案中学习,监督学习的两种主要类型是回归和分类,在回归应用程序中,学习算法必须从无限多可能的输出数字中预测数字。但在分类上,学习算法必须对一个类别做出预测,所有一小部分可能的产出。
无监督学习
聚类算法
在上面的例子中,每个示例都与一个输出标签y相关联,例如良性或恶性,在无监督学习中由两极和十字表示,给定的数据与任何输出标签y无关,比如给定了有关患者及肿瘤大小和患者年龄的数据。但不是肿瘤时良性还是恶性,所以数据集在右边看起来像是这样:
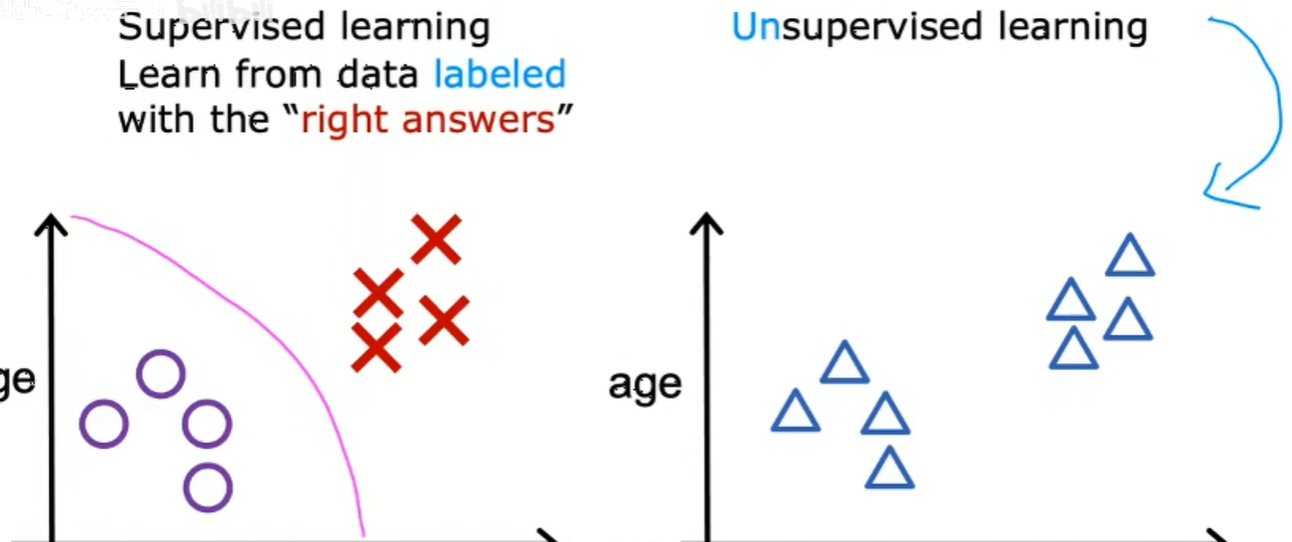
我们没有要求诊断肿瘤时良性还是恶性,因为没有给我们任何标签,为什么在数据集中,相反,我们的工作时找到一些结构或模式或只是在数据中找到一些有趣的东西,这就是无监督学习,我们称它为无监督学习是因为我们不试图监督算法。相反,为了对每个输入给出一些引用正确的答案,我们要求我们的房间自己弄清楚什么是有趣的。
简而言之就是,我们不让程序帮助我们判定输入x之后给出的输出y是什么,这部分由我们自行判断。它的作用就是在执行算法,给出结果。至于我们对结果怎样解析,这并不是程序该关心的。
无监督学习算法可能会决定将数据分配给两个不同的组或两个不同的集群。所以它可能决定这里有一个数据组或者是另一个地方有一个另外的数据组,这是一种特殊类型的无监督学习,称为聚类算法。
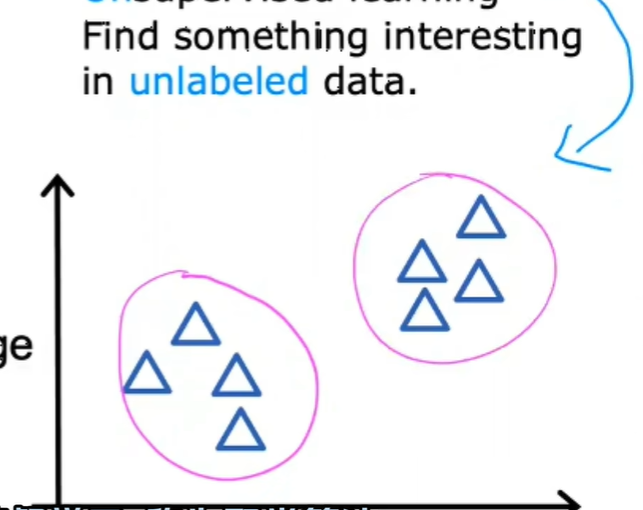
它将未进行标记的数据放入不同的集群中,用于不同的功能,比如放入到判断癌症的程序中,它就是判断良性恶性。
比如google news 用的是聚类算法,它做的就是天天去查看互联网上数十万篇新闻文章,并将相关故事组合在一起。比如你现在看一个文章,或者在购买一个物品,在文章或者物品下面是相关的其他东西,他就开始猜你喜欢了。所以聚类算法正在不断的找文章或者物品,提取到相似的词或者标签将他们分组到集群中。这是没有人工参与的,没有一名员工告诉算法查找包含你购买的东西或者你正在查看关于包含熊猫关键词的文章。
算法必须在没有监督的情况下自行计算出今天的新闻文章有哪些。这就是为什么这种聚类算法是一种无监督学习算法。
再简而言之就是:没告诉机器应该给出什么结果,而是让机器去分别出不同的标签。
在监督学习中,数据同时带有输入x和输入标签y而在无监督学习中,数据仅带有输入x而没有输出标签y并且算法必须在数据中找到结构。
异常检测
异常检测,用于检测异常事件,事实证明,这对于金融系统中的欺诈检测非常重要,异常事件,异常交易可能是欺诈的迹象,对于许多其他应用程序也是如此。
降维
这使您可以将一个大数据集神奇地压缩成一个小得多的数据集同时丢失尽可能少的信息。
- Post link: https://www.godhearing.cn/wu-en-da-ji-qi-xue-xi-1-gai-nian/
- Copyright Notice: All articles in this blog are licensed under unless otherwise stated.