前言
协同过滤算法,这是一个比较著名的推荐算法,其主要的功能就是预测和推荐,算法通过对用户历史行为数据的挖掘发现用户的偏好,基于不同的偏好对用户进行群组划分并推荐品味相似的商品,协同过滤算法分为两类,分别是基于用户的协同过滤算法和基于物品的协同过滤算法,简单的说,就是物以类聚,人以群分。
基于用户的协同过滤
基于用户的协同过滤算法是通过用户的历史行为数据发现用户对商品或内容的喜欢(如商品购买,收藏,内容评论或分享),并对这些喜好进行度量和打分。根据不同用户对相同商品或内容的态度和偏好程度计算用户之间的关系。在有相同喜好的用户间进行商品推荐。
说的再简单点,就是,你去买了一个XX手办,对它评价挺高,然后有一个路人甲也买了一个XX手办,评价和你很类似,然后根据算法算出你们的喜好可能是相近的,所以,下次路人甲买了其他的商品,也会把这件商品推荐给你,因为你们的相似度很高。当然了,这就是一个例子,商品的数量足够多,那么,推荐的也就越准确。
实现这个协同过滤算法的第一个重要步骤就是计算用户之间的相似度。而 计算相似简历相关系数矩阵目前主要分为:
- 皮尔逊相关系数
- 基于欧几里德距离的相似度
- 余弦相似度
我们这里就说基于欧几里德距离(又称欧式距离)这一种。
欧式距离计算相似度是所有相似度计算里面最简单、最易理解的方法。它以经过人们一致评价的物品为坐标轴,然后将参与评价的人绘制到坐标系上,并计算他们彼此之间的直线距离。计算出来的欧几里德距离是一个大0的数,为了使其更能体现用户之间的相似度,可以把它规约到(0.1]之间,最终得到如下计算公式: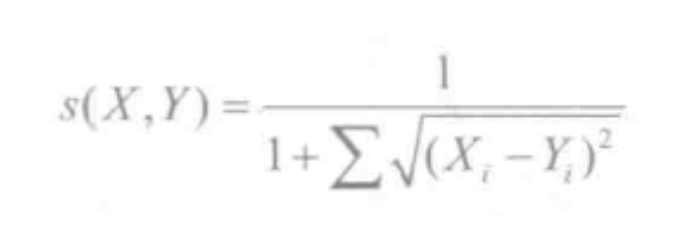
只要有一个共同评分的项,就能用欧式距离计算相似度,如果没有共同评分项,那也就意味着两个用户或者物品并不相似。
python实现协同过滤
我们使用代码来实现一下协同过滤,我们首先创造模型,比如说,我们都喜欢看动漫,我们就可以根据个人的喜好来进行推荐,首先,新建txt文件,名字随意。
1,海贼王,2.0
1,火影忍者,5.0
1,全职猎人,2.6
2,刀剑神域,1.0
2,海贼王,5.0
2,犬夜叉,4.6
3,画江湖,2.0
3,全职高手,5.0
3,喜羊羊与灰太狼,2.6解释一下:1喜欢看海贼王,给出了2.0的评分。以此类推,可以看到,1、2、3三个人中,只有1和2喜欢看海贼王,这也是他们之间唯一的交集。
content = []
with open('./comic.txt') as fp:
content = fp.readlines()
print(content)首先,读取,这里就不用多说了。
# 将用户、评分、和动漫写入字典data
data = {}
for line in content:
# 处理掉多余的空格并分割
line = line.strip().split(',')
# 如果字典中没有某位用户,则使用用户ID来创建这位用户
if not line[0] in data.keys():
data[line[0]] = {line[1]: line[2]}
# 否则直接添加以该用户ID为key字典中
else:
data[line[0]][line[1]] = line[2]
print(data)def Euclid(user1, user2):
# 取出两位用户看过的动漫和评分
user1_data = data[user1]
user2_data = data[user2]
distance = 0
# 找到两位用户都看过的动漫,并计算欧式距离
for key in user1_data.keys():
if key in user2_data.keys():
# 注意,distance越大表示两者越相似
distance += pow(float(user1_data[key]) - float(user2_data[key]), 2)
return 1 / (1 + sqrt(distance)) # 这里的返回值越小,相似度越大计算某个用户和其他用户的相似度
def top_simliar(userID):
res = []
for userid in data.keys():
# 排除与自己计算相似度
if not userid == userID:
simliar = Euclid(userID, userid)
res.append((userid, simliar))
# 排序
res.sort(key=lambda val: val[1])
return res可以看到,与其他两位用户的相似度已经被推算出来了。
接下来,我们可以根据相似度来进行推送,按照我们这个例子,1和2之间是唯一有交集的,如果我们要给1推送,也只能推送2看过的,也就是犬夜叉和刀剑神域。
def recommend(user):
# 相似度最高的用户
top_sim_user = top_simliar(user)[0][0]
# 相似度最高的用户看过的动漫
items = data[top_sim_user]
recommendations = []
# 筛选出该用户未看过的动漫
for item in items.keys():
if item not in data[user].keys():
recommendations.append((item, items[item]))
recommendations.sort(key=lambda val: val[1], reverse=True) # 按照评分排序
return recommendationsok,结果还算不错,按照我们所想。
- Post link: https://www.godhearing.cn/xie-tong-guo-lu-suan-fa/
- Copyright Notice: All articles in this blog are licensed under unless otherwise stated.